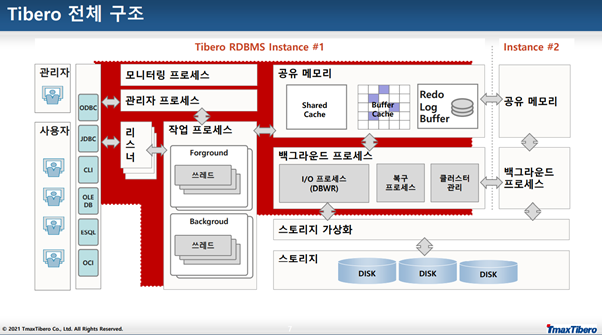
빨간영역이 인스턴스, 스토리지가 데이터베이스이다.
순서
1. 사용자가 인터페이스를 통해 리스너에게 요청
2. 리스너를 통해 워킹 프로세스로 접근
3. 공유메모리 혹은 공유메모리에 없다면 스토리지에서 내용을 가져와 사용
(스토리지 : 디스크, 메모리 : ram)
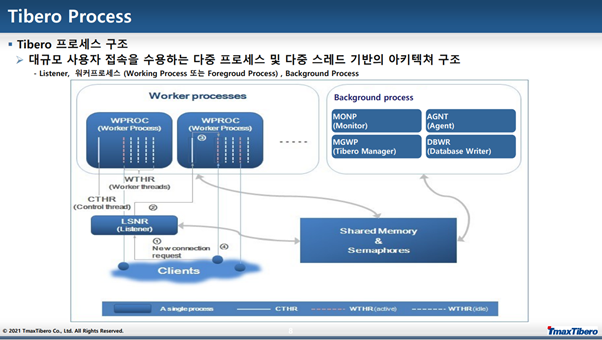
순서
1. 클라이언트가 리스너에서 접속 요청
2. 리스너가 현재 빈 WTHR이 있는 프로세스를 찾아서 이 사용자의 접속 요청을 CTHR에 요청
3. CTHR이 WTHR중 일하고 있지 않는 하나에게 일을 할당(내용이 없다면 공유메모리에서 찾아봄)
4. WTHR은 Client와 인증 절차를 걸쳐 세션 시작. 처리 후 클라이언트에게 반환
리스너
클라이언트의 새로운 접속 요청을 받아 이를 유휴한 워커 프로세스에 할당
리스너를 alter문으로 추가하는 법 : alter system listener add port 0000;
(tbdown시 초기화됨)
CTHR (Control Thread) : 각 Working Process마다 하나씩 생성.
서버 시작 시에 지정된 개수의 Worker Thread를 생성. - 시그널 처리 담당. - I/O Multiplexing을 지원하며, 필요한 경우 워커 스레드 대신 메시지 송/수신 역할 수행.
WTHR (Worker Thread) : 각 Worker Process마다 여러 개 생성.
Client 가 보내는 메시지를 받아 처리하고 그 결과를 리턴. - SQL Parsing, 최적화, 수행 등 DBMS가 해야 하는 대부분의 일 처리.
Foreground process , Parallel process는 죽여도 기동은 됨..
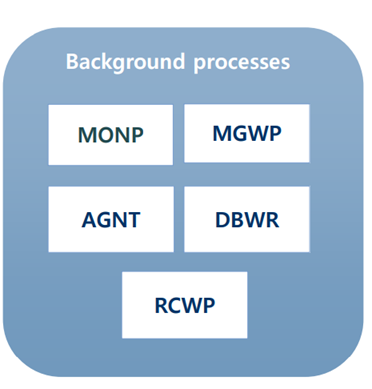
§ Background Processes : 이 프로세스는 죽이면 티베로가 전체 다운이 됨. 주의하세요,,,
감시 프로세스(MONP: monitor process) : 티베로 기동 시 가장 먼저 기동되고 가장 나중에 종료. 해당 프로세스가 기동되어 나머지 프로세스를 기동시키기 때문. 교착 상태 (Deadlock) 검사
매니저 프로세스(MGWP) : 관리자의 접속 요청을 받아 이를 시스템 관리 용도로 예약된 워커 스레드에 접속을 할당
세션이 가득 찼을 경우 리스너 포트를 통해 포워그라운드 프로세스로 접속하는게 아닌,
스페셜 포트를 사용해 매니져 프로세스로 접속
에이전트 프로세스(AGNT : agent process) : 시스템 유지를 위해 주기적으로 처리해야 하는 Tibero 내부의 작업을 담당
세션이 죽었을 때 주기적으로 처리해야하는 작업을 포워그라운드 대신 해줌
(매일 12시에 어떤 일을 해줘!) – 별로 중요하진 않음,,,,그래서 테스트할 때 가장 많이 죽임
데이터베이스 쓰기 프로세스(DBWR) : 데이터베이스에서 변경된 내용을 디스크에 기록하는 일과 연관된 스레드들이 모여 있는 프로세스 (Redo log 기록 스레드, 체크포인트 스레드등이 포함)
bin폴더 안의 tbiobench를 이용하여 디스크 성능을 측정해보자,,,
/tibero에서 tbiobench -i all -s 100M -F O_SYNC -F O_DIRECT –k
5~10Mbytes/sec 이하로 나오면 담당자에게 고지해 줄 필요가 있음…(스토리지 업체에 문의하세요,,,,나 말고,,,)
TSN : 데이터베이스 내의 시계 같은 거라고 생각하면 됨
Checkpoint : 특정 시점까지 일관성을 기록하기 위해 사용
Alter system checkpoint;
alter system set nls_date_format='YYYY/MM/DD HH24:MI:SS';
alter session set nls_date_format='YYYY/MM/DD HH24:MI:SS';
복구 프로세스(RCWP)
Crash (비정상종료 시 복구) / Instance Recovery 수행
(Redo,Undo 이용)
Memory_target : DB 전체 메모리,
TOTAL_SHM_SIZE : 공유 메모리만의 사이즈
TOTAL_SHM_SIZE는 싱글일 시 MEMORY TARGET의 2/3, TAC기준은 절반
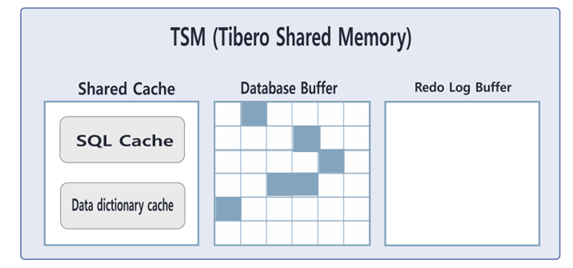
SGA(TSM) : 모든 세션 공유하며 사용할 수 있음
SQL cache(실행 계획) ,
redo buffer (buffer cache) : redolog에 입력될 정보를 잠깐 저장하는 것..
Data Dictionary cache(DB에 대한 모든 정보가 기록,테이블 크기, 인덱스, 유저의 속성 등등…).
Database Buffer : 메모리에 해당 데이터가 없을 때 스토리지에서 데이터를 끌어올리는데 그 내용이 들어가는 곳
PGA(WPM) : 세션마다 개별적으로 사용
쿼리를 실행시키는 공간 (더 자세한 자료는 KSS 참고)
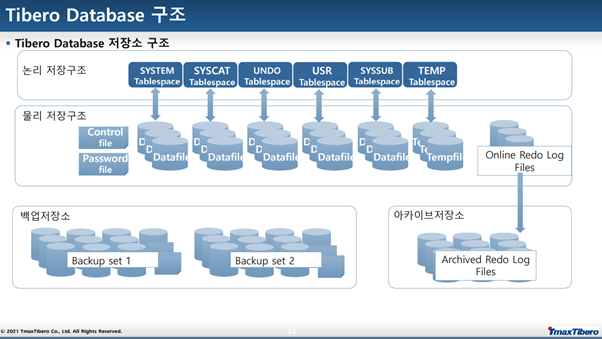
논리 저장구조 :
(1) SYSTEM : 데이터베이스 관리 정보를 포함한 테이블, 뷰
(2) UNDO : 언두 데이터 (언두 세그먼트)
(3) SYSSUB : TPR의 스냅샷 데이터
(4) USR : TIBERO, TIBERO1 유저의 default tablespace
(5) TEMP : 정렬 작업용 데이터, 세션의 유지 기간만 저장되는 임시 데이터
Tablespace - 물리적으로 그룹화된 데이터를 위한 논리적 저장 단위, 한개 이상의 데이터 파일이나 임시파일을 사용하여 데이터를 저장함
물리 저장구조
Datafile : 데이터의 실제 정보를 담고 있는 파일
Controlfile : 데이터를 담고 있는 파일의 주소를 담고 있는 파일
Redo log file : 데이터가 변경될 때 마다 기록되는 파일
아카이브 저장소
Archived redo log file : 아카이브 모드시 Redo log file을 읽어옴
백업저장소
오류 발생 시 해당 저장소에 있는 데이터로 Recovery 실행
RAW 장치
파일시스템으로 포맷되어 있지 않은 디스크 파티션 혹은 논리 볼륨으로, 파일시스템과 달리 캐시를 거치지 않고 직접 I/O 를 수행할 수 있음 (파일시스템과 비교하여 가격이 싼 대신 어려움, I/O 성능이 잘 나옴, 관리가 어려움)
'Tibero > 아키텍쳐' 카테고리의 다른 글
| tbdown 옵션 정리 (0) | 2023.01.26 |
|---|---|
| tbboot 단계 정리 (0) | 2023.01.26 |
| 티베로 설치시 기본적으로 생성되는 파일 정리 (1) | 2023.01.19 |
| HA (High Availability), TAC, TSC (0) | 2022.12.28 |
| Tibero 아키텍쳐 정리 2 (0) | 2022.12.22 |